I’ve recently had the opportunity to put into practice my aptitude and thoughts on microservices and message queues. For this first article I will focus on the RabbitMQ ecosystem for message queues. As I have gained a breadth of practical knowledge, I have written down and linked to each topic I’ve covered along with some thoughts and examples, where applicable. This article is a collection of the lessons I have learned so far, and is intended to be a practical/semi-technical summary of concepts that come to mind.
The following keywords have been capitalised throughout the article: Consume(r), Produce(r), Message(s), Service(s), Exchange(s)
And also a large thank you to those who gave me the time to get my head around their system, and gave me a step-up to learn more in my own time.
Articles in this series:
- Overview: Recent Experience with Message Queues
- Implementation: Testing Message Queue Strategies – AWS, Proxmox, and Monolith (On hold)
- Auto-Scaling: Scaling with Microservices and Message Queues (On hold)
Unfortunately due to personal circumstances and time commitments the additional articles in this series are currently on hold
Sections
- Message Queueing systems
- –Message Queueing: In Practice
- –Message Queueing: Building in Automation?
- —Example: Automated message flows
- –Message Queueing: Handling speed and errors
- —Handling: Queue speed: Acknowledge
- —Handling: Queue speed: Service slowdown
- —Handling: Queue speed: Queue slowdown
- —Detection: Lost Messages
- —Logging: and general error handling
- Message Queues for the Monolith
Message Queueing systems
Message queues provide a shared system for Message flow. Rather than having an intricate system for marrying senders to receivers, Message Queue’s provide a way to Queue messages for Services to Consume from at will.
Popular Message queue systems include RabbitMQ and Apache Kafka. In this article I will be focusing on RabbitMQ’s features as I have practical experience with it.
Message Queueing: In practice
To give a practical summary, Message queue’s allow you to define a system for processing packages of data (Messages) by passing them around via queues. This system can be additive, subtractive, destructive, or otherwise manipulative of the data in Messages. The Services handling these messages do not have to preserve data, and must be designed and implemented to do so. Each Service registering as a Consumer to a queue has the potential to edit, corrupt, or otherwise destroy Messages and their contents once receipt is acknowledged. The default behaviour of a message queue is to preserve messages until they are pulled from, and they are acknowledged.
Producers (Services that create, and/or forward Messages) put Messages onto a queue. Consumers (Services that pull Messages from a queue) pull messages from a queue to interact with the contents in some way. Conceptually, from these you can make systems with many number moving parts that Consume and Produce Messages directly into many queues to communicate and process data. Essentially, this loosely defines a process or sequence to be followed.
At this level of complexity, dealing with queue’s directly, the basic Message flow is as follows:
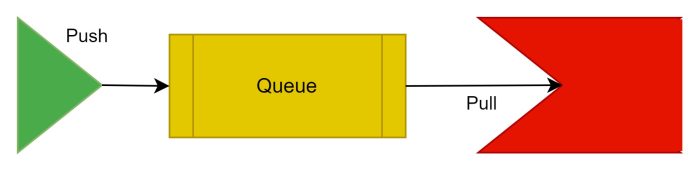
Note: You may wish to stay at this level of complexity when dealing with Message queues. Beyond utilising queues directly there is an increased burden to utilise vendor specific implementations of message handling. Handling Message queue choice within the Services themselves may be preferable to prevent any vendor specific implementations. This vendor lock-in may become technical debt in the circumstance where a different vendor is needed/wanted.
Beyond this article, RabbitMQ also provides Queue usage in their tutorials section. The above diagram describes a basic “Hello World!” style interaction with a Message queue.
Message Queueing: Building in Automation?
The RabbitMQ Tutorials page additionally describes the exchange and Stream-Queue components. I will focus on the exchange component for the moment. The exchange can be used to automate message flow depending on the implementation chosen. Before explaining a few of the techniques I have tested, a short explanation of the exchange and it’s modes of operation:
The exchange:
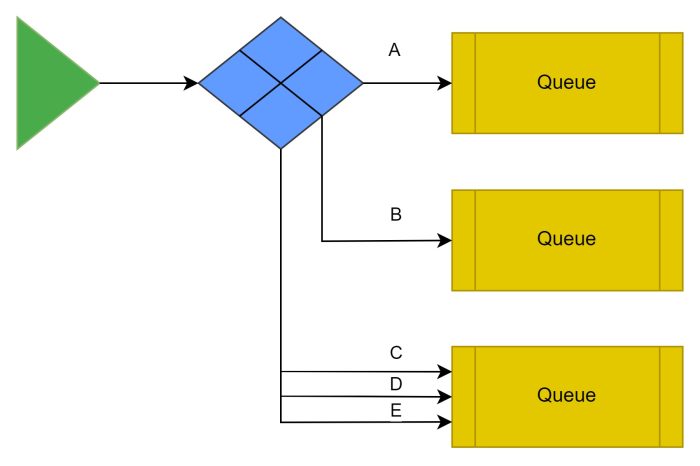
Several types of Exchange exist. The above is an example of a direct Exchange. Generally, the type of Exchange determines how it routes and the technique/method used to do so. Whereas the bindings from Exchange to Queue, determine the rules and where Messages can go/are routed.
The operation of the Queue types is summarised below:
| Type | Routing | Duplicates Messages? |
| Direct | Messages with a key, are routed directly to queues bound with that key: Message with Key “A” -> queue bound with key “A” | When bound with the same key |
| Topic | Messages with a key, are routed depending on a queue’s routing pattern: Message key “A.B.C” -> queue bound with pattern “A.B.C” and queue Pattern “A.#” (# any more words) and queue Pattern “*.B.C” or “A.B.*” (* any single word) | When the routing key matches the pattern of multiple binding patterns |
| Fanout | This exchange ignores bound queues routing keys, and duplicates the message to all bound queues | To all bound |
| Headers | Uses Message Header values to exchange. Bindings can set matching to all headers (x-match: all)(default), or any headers (x-match: any) | All matching header configurations |
These exchanges can be used in conjunction with queues and Message tags (Keys and Headers) to automate the transport of Messages around a system.
Example: Automated message flows
I have designed the following systems around business processes I’m aware of.
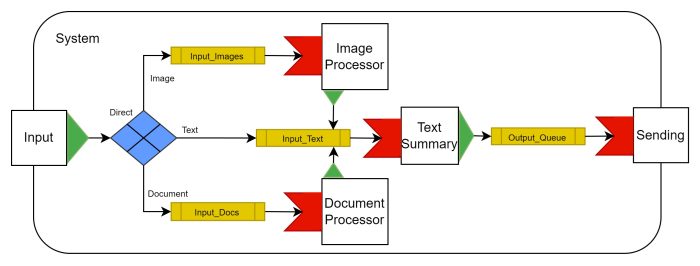
As a basic example, in the above system images and documents are directed to their own pre-processors, before utilising their output for textual summary generation. In this system, the input tags each Message with it’s type Key before publishing the Message to the Exchange.
Note: The Messages in these examples don’t need to contain full files. They may contain references to an external file share instead.
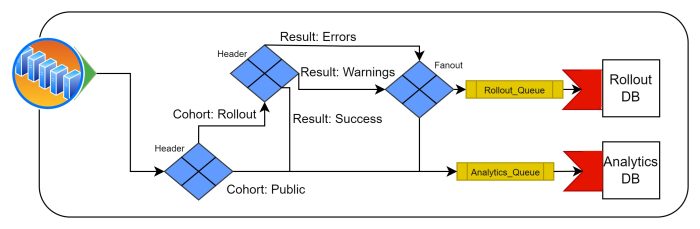
It is also possible to bind exchanges together. In the example above, the system is pre-sorting update results from deployed devices. This system is designed to aid visibility when rolling out updates to devices. In an update rollout, deployed devices are onboarded into larger and larger cohorts for the new update until it is open to the public. In the above design, updates from devices enrolled in the rollout who’s updates errored or encountered warnings are also sent to a secondary “Rollout DB”. This would allow for accurate tracking of defects, and quick detection of issues without the need to search through a larger main database.
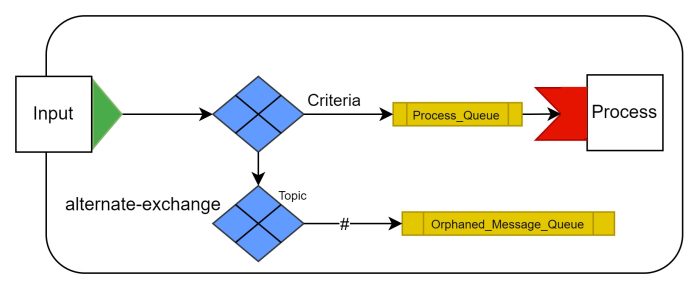
I believe the above design would be useful to prevent message delivery failures more elegantly when the criteria used for forwarding isn’t necessarily predictable. I’m considering it an equivalent of “if-else” due to the way it handles undelivered Messages. This happens by declaring the second exchange an ‘alternate-exchange’ of the first during Exchange creation. So ‘if’ a Message is undeliverable to any existing bindings, the Message is passed to the ‘alternate-exchange’ instead of being unhandled. This would make detecting and re-processing orphaned Messages easier.
In case of errors there are also “dead letter exchanges“, which can be used to further route rejected/timed out Messages.
Message Queueing: Handling speed and errors
I have come across some interesting challenges around Message queues.
The primary areas are around errors, logging, and the speed (both of the queues themselves and Message processing by services). There is an additional section on potentially catching lost Messages.
Handling: Queue speed: Acknowledge
Because Consumers pull from queues, and queues prevent Message loss, each Message that has been pulled but not acknowledged is an overhead for the Message queue.
One way of resolving the speed issue on the queue is to acknowledge the message as soon as it is pulled into the Service, lowering the queue depth for RabbitMQ (or similar) to handle. When we do this, we are changing the fundamental premise of acknowledging from “I am done with the Message” to “I have the Message”, and there is now a risk we will lose the Message permanently if there is an error. This is because acknowledging a message removes it from the queue it was just pulled from and that could be the only copy of the Message. Queues can be set to do this automatically with the “autoack” setting. If queue speed is a necessity and this is the solution, I have considered a method of detecting Messages lost in a system in the section “Detecting: Lost Messages” further down.
The general routine for ensuring preservation of Messages in the case of Service failure/crashes/bugs is to engage in the following within a service:
- Wait for / Pull new Message
- Process the Message
- Send the output to the next queue/other method
- Acknowledge the Message (when manual acknowledgement/similar is active)
- Repeat
If the service crashes or otherwise fails to operate, the Queue can send the unacknowledged Message to a different service instance for processing after a timeout.
This may also occur, and cause a double Consumption, if the Message is difficult to process. The queue’s timeout should be changed if the rate of processing is known, to prevent this double Consumption.
Handling: Queue speed: Service slowdown
While not directly a Queue issue, the queue is impacted when service instances do not process Messages efficiently. From what I have seen so far, RabbitMQ Queues seem to engage in round robin despatch of Messages to registered Consumers. On it’s face, this is not a problem. But not all Messages carry the same processing burden.
When Messages take differing amounts of resources to process, it can help to set the channel prefetch limit. This sets a limit on how many messages are earmarked for each service instance. This ensures that non-earmarked Messages are sent to less congested service instances, increasing overall system throughput and preventing newly queued Messages from waiting on a congested Service instance.
Addendum: Beyond Message processing variability, it may be that the Service itself is at issue. Performance may be on the table if the Service codebase itself is not written performantly. If you are targeting a Service which pulls multiple Messages for processing, it may be appropriate to multithread or look into taking advantage of SIMD(Single Instruction Multiple Data) where possible to speedup processing. Each of these will require analysing the Service to determine if there is wasted or idle CPU time, and if the re-engineering is compatible with the intended hosting arrangement.
Handling: Queue speed: Queue slowdown
Queue slowdown can be due to small amounts of Messages being requested by multiple Consumers. This makes it more difficult for the Queue to manage Messages.
Services have the option of requesting a larger ‘batch’ of Messages at once. So a solution may be to reconfigure Service instances to: Process more Messages in parallel per instance; and have more resources at hand to do so such as virtual CPU’s and RAM.
The caveat of this approach is the same variable Message processing problem described in “Service Slowdown” above. If Messages are variable in their processing burden, additional logic is needed to Consume a variable number of additional Messages and Publish a variable number of Messages to maintain throughput.
Another potential solution (without sacrificing Messages through a queue max-length) is to venture into multiple nodes with High Availability. But I have not yet covered this myself.
Detection: Lost messages
Because it is possible for Messages to disappear in Services (e.g. when auto-acknowledged), it needs to be handled when possible. It may be wise to include a sub-system around the intended Message queue, to account for (and potentially re-transmit) lost Messages.
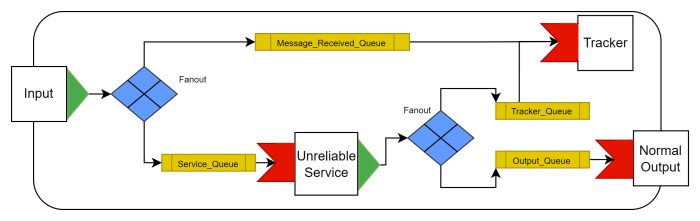
This would involve implementing a tracking mechanism/functionality whereby Messages leaving the system are compared with Messages which entered. In this circumstance it may be more applicable to use a “Stream” for the initial Message copy. This would allow the Tracker to search the stream, rather than destructively reading them from a queue and needing to hold multiple Message copies, potentially losing them.
To make the logic for Tracking simpler, this design could uniquely tag Messages at the input with an inserted hash or similar. This would simplify the logic needed to detect Message loss at the Tracker.
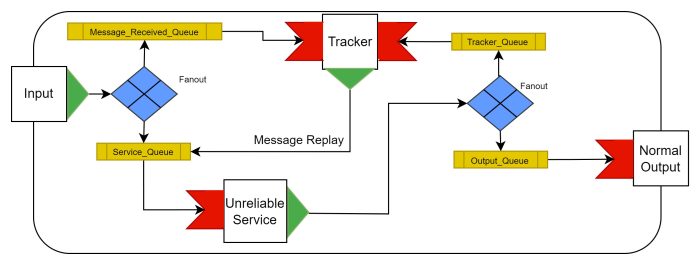
Additionally, once Message loss is established the design could be improved by allowing the Tracker to replay the Message into the “Service_Queue” (as in the diagram above). If the replayed Message is then re-encountered at the exit, it can be considered successfully processed. This presumes that the unreliability is not due to the Message contents, and that either whole Message contents or only a unique Message/Task identifier is re-transmitted by the Service.
Logging: and general error handling
Capturing logs can be achieved through the usual method of being Produced in a Service and adding it to a queue or similar. The Messages stored can then be Consumed and sorted by an external Service/Program, or otherwise handled/read.
The remainder of this segment lists some additional error handling and the areas I am looking into and my thoughts:
- Dead letter exchanges – Handling when a message is rejected or otherwise expires
- Handling double message Consumption
- When a Message times-out whilst being processed by a Service, it is put back on the queue. Sometimes this is not due to the Service failing, but because the Message is difficult to process. The same Message is then re-processed to other Services, and this can potentially spread to all available Service instances
- Similarly ‘broken’ Messages (which will be implementation specific) will never be correctly processed. Identifying these would be useful and prevent Service degradation. Dead letter exchanges may be useful here, to handle actively rejected messages
- Consider adding a retry count to the contents of the Message, and returning it to the queue with a reject and requeue it. Rejecting it to a dead letter exchange when a max retries is met
Message Queues for the Monolith
When Studying Message queues I have come across another potential option for scenarios where a highly performant monolith is preferred.
Message queues which are built into the application themselves skip the network layer of a distributed system, and allow some decoupling within a monolith. https://github.com/rigtorp/MPMCQueue
MPMCQueue is one such example, and is in use where latency sensitivity is critical, such as high intensity games and low latency trading infrastructure.