Unfortunately, we won’t be covering any of the arguments regarding simulation theory. But, I am offering a method to detect whether code is running in a virtual environment and this article as a very casual summary of it. Including generating some new data! and graphs!
As usual, this next section is for quickly hopping between sections:
“Is this code running in a virtual environment” is the question several codebases ask. Both malware and cheat detection programs are notable examples of software that wants the answer to this question.
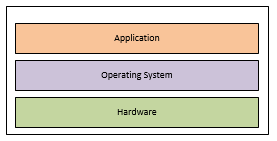
Normally code is running on your computer via a pre-made application:
This is the normal situation for most applications. We log-in to Windows and open our favourite apps. But we have special cases such as “the cloud” and other peoples servers where code is also ran.
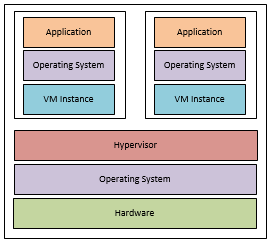
In these cases the code (Application) is not running directly on top of the usual operating system and hardware:
A “Tier 2” hypervisor, “host-based”/”Hosted”A “Tier 1” hypervisor, “Bare-metal”
This code (and Application) is not running traditionally. It is (at some point) running under some hind of Hypervisor. The whole machine is sharing it’s resources between several “virtual machines” via this hypervisor.
So what’s actually different and why does this matter?
Well, to skip over a lot and overly simplify things a tad, not every part of every bit of code that usually runs in your computer works/is trusted when running in a Virtual machine(VM). The Hypervisor needs to catch these and handle them differently. These “privileged instructions” need to be handled specially by the hypervisor for a variety of reasons.
So, a “privileged instruction’s” journey usually looks like this:
But, ends up looking something like this when running in a VM:
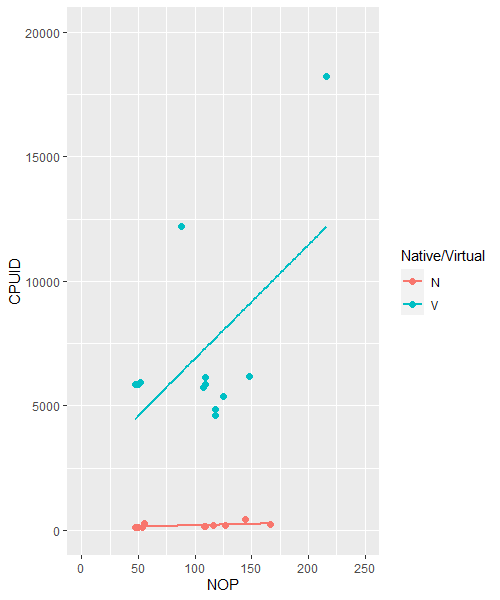
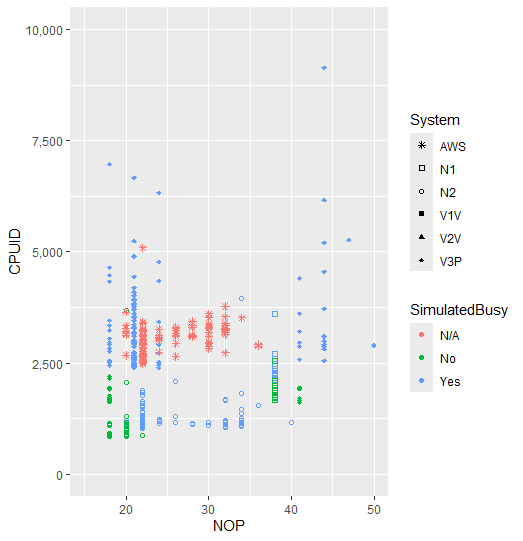
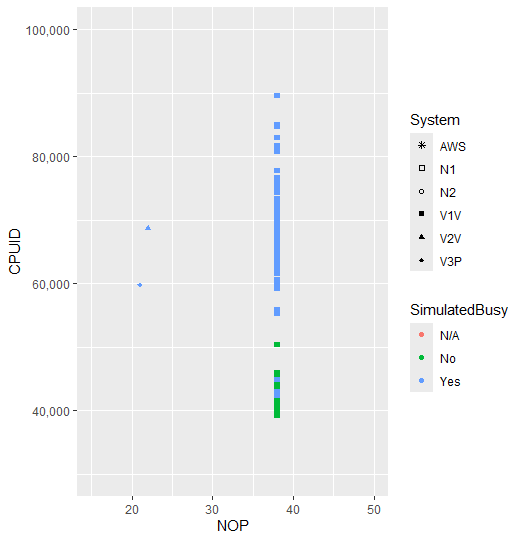
And that’s usually much slower than non-privileged code. In my project I timed two instructions to see if there was a discernible difference as stated in existing research papers. One of my graphs showed a comparison between the timing of a privileged instruction (CPUID) and the timing of a normal instruction (NOP)(which actually does nothing but is still useful):
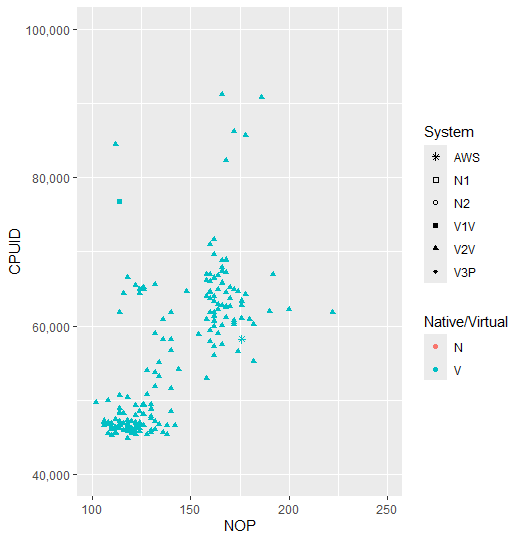
And we can see that this intuition plays out. A clear distinction between the time it takes a CPUID instruction and NOP to run in Virtualised vs Native (non-virtualised/normal) instances.
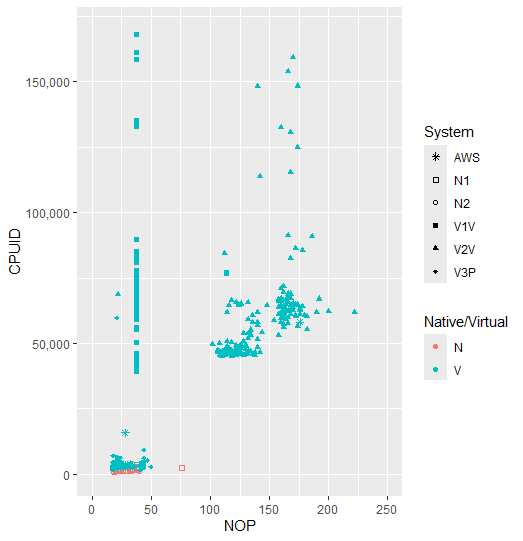
There is still a clear difference between virtual and native operation for the most part. But this is mainly due to the use of VirtualBox for the middle and left clusters. Having a closer look at the Native results in the bottom left…
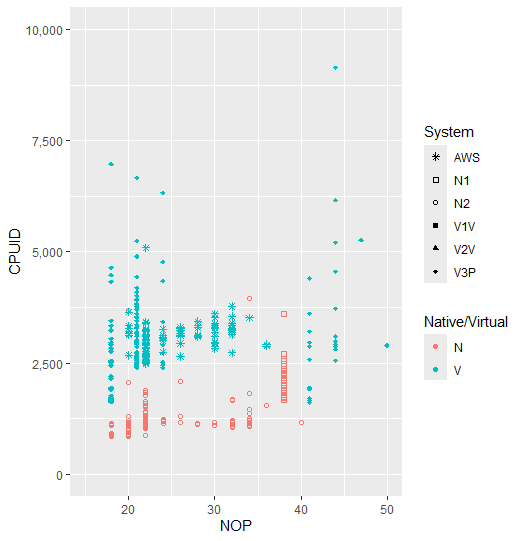
…We can see that there’s still a clear division between normal timings and virtualised timings. The testing also used simulated “busyness” on the system to simulate a high use system, such as intense gaming/other workloads. Simulated busyness can be seen to have a definite affect on the speed of the measurements, but not enough in the Native execution to start to become indistinguishable from the virtual results.
Given the initial graph it seems like a simple dividing line would still be appropriate with minimal false-positives.
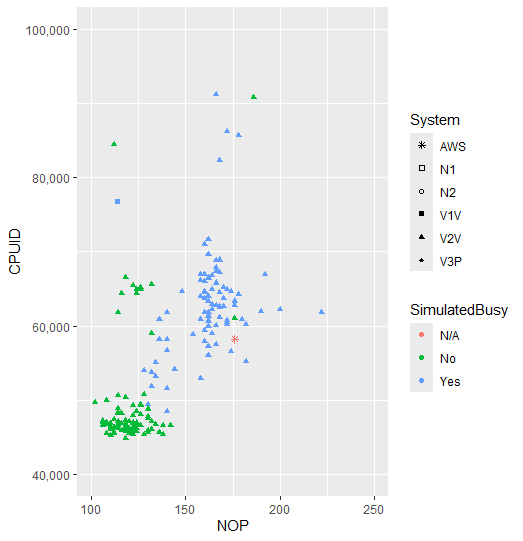
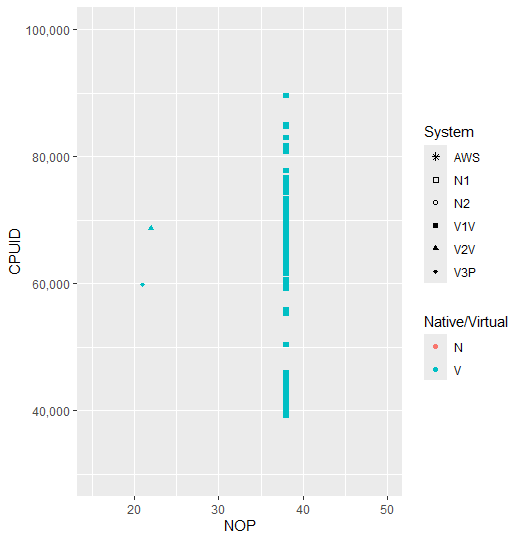
The repository holding the results is here. The remaining close-ups of the other clusters are as follows:
AWS – AWS Microsoft Windows Server instance c5.xlarge
Previous data/research
Originally I had an incredibly ambitious idea of the amount of work was achievable given the time I had at University. Many of the comments, intentions and the Readme.md especially, are not entirely accurate to the end scope. I’ve certainly improved considerably since leaving university, but I will share the repository without edits and with a repeated caveat emptor regarding applicability.
An educational institution, loosely modelled after the
university of Plymouth, requires a new datacentre to support operations. The
datacentre is required to support administrative operations specifically. These
operations include web, and file storage capabilities.
There are two types of employee in the administration.
General Information (GI) which complete general tasks, and staff which handle Sensitive
Information (SI) such as disability/health related documents.
A web site supporting GI employees, is required. This will
hold the employee self-service system, responsible for expense claims,
contractual information, payroll and holiday authorisation. SI employees will
also have access to this system for their general needs. This includes an SQL
backend, storing data, and receiving requests from web servers.
A file server for SI employees to store supporting
documents, is also needed, and required to be secure.
Estimates
Peak usage
To estimate usage, it is assumed that there are five
departments, with fifteen staff each. Twenty percent of which are SI staff. For
a total of seventy-five, of which fifteen access SI resources.
To estimate GI services, the Moodle website will be used. On
initial load the main page transfer takes 2.5MB. Subsequent loads transfer
1017kb. The load comes from GI staff using the services to perform their
duties. It is assumed that a GI staff member will request 80 pages per hour. At
seventy-five staff this comes to a peak of, 6000 per hour, 100 requests per
minute, or roughly 0.816 Gigabits of throughput.
SI services require file transfer. After the GI requests
there is 23MBs of headroom for file transfer. It is assumed that Si staff
behaviour, is to upload files to the SI file server for filing and storage,
after sensitive paperwork has been submitted. The processing of paperwork by SI
staff is for one file per 20 minutes. Assuming a file size of 1.2MB, at fifteen
SI staff, this equates to 54MB per hour. Which is less than 1MBs average. With
TCP Windowing, file transfer will exceed this speed briefly but should not
reach 23MBs, even with fifteen users.
Light use on main SI server, allows for its resources to be
timeshared with the GI server. Migration of VM’s from the high load of the SE
server to the SI server, will maintain a high degree of reliability and speed for
the datacentre as a whole.
Hardware
Cabling
The traffic estimation concludes that standard gigabit
cabling is sufficient to handle client requests to and from the GI services. As
well as file transfers for SI staff. Each server will need at minimum two
Gigabit Lan ports, and a lower speed 100/100 port. The GI VLan requires ~0.8
Gigabits of throughput. The management VLan requires Gigabit throughput for
after hours backups. And the SI VLan does not need much throughput.
Storage
The storage requirements come from the SI file storage
server. At 23,000 students and an estimated incidence of disability between 0.8
and 5.7 (The Office for Disability Issues,
n.d.),
I estimate the percentage of university students to be near two percent. This
gives an estimated number of students with SI files of 460. At minimum the
storage requirements would be 8GB. This includes medical documentation, as well
as extenuating circumstances for four years.
Each apache VM for processing web requests will take up 10GB
for web resources.
The SQL server will take up more space than the Apache VM’s,
and is a singular server instance holding the data for the GI service. 100Gb
will be provisioned for this VM.
The load balancing VM’s storage will be minimal at 3GB as
this mainly requires processing.
In total, a minimum of 132GB. With two apache VM’s. This
storage will reside on a shared SAN.
Processing
Both servers will be hardware identical to allow for
failover I the event of hardware failure. This means that each server needs to
handle the requests for the entirety of the GI and SI services if the need
arises.
This will require each Server to have a threading capacity
of at least 9 threads. Three for load balancing, and web VMs. And three each
for the file, and SQL VMs.
RAM
1GB for each load balancing, and web VM, at least three. 2GB
for the SQL server, to ensure efficient processing of requests. 2GB for the
File server. A total of 7GB.
Implementation
Security
Security in the design is provided by the segmentation in
place. The VLan’s limit the ability for potential vulnerabilities to be
leveraged. In the event an attacker is able to access a VM. They will only be
able to attack other areas of their respective VLan.
The management VLan is only available through physical
access. No forwarding is done by the router, and internet access is monitored
by an IDS. The GI VLan is accessed through the router by port forwarding ports
80 and 443, for HTTP and HTTPS respectively. This allows GI users to easily
access the GI site. As the site is not forwarded to the internet, it will not
be targeted by automated scans.
Hardware
Disks
Direct attached storage will be used for each server. Each server’s
disks are part of a five disk RAID array configured in RAID 5. This gives a
storage efficiency of 80 percent. Each disk will store 250GB, meaning a total
array, per server, of 931GB after efficiency.
This RAID implementation will allow high performance, as
write and read operations can overlap. Write operations will require the
recalculation of the parity information, but this write operation will occur on
a different disk from the origin write. So should not impact performance significantly.
Disk failure is also mitigated through the distributed parity information. The
array will still be able to function with one disk failure. However, a
successive failure within this replacement window could cause the array to
fail, especially with batch-correlated failures.
To mitigate batch-correlated failure from the use of disks
from the same batch. It is recommended in this instance to diversify the origin
of disks, in both manufacturer and production batch (Paris &
Long, 2006).
Disks will be procured from entirely different manufacturers and batches, used
and evenly allocated to the SAN to maximise disk diversity. Spares from this
process will be kept stored for the event of disk failure, to be immediately
swapped for array rebuild. This would reduce the likelihood of batch-correlated
failure from 63% to 0.02%, when replacing a failed disk within one day. The
mean time between failures for the 5 disk array is near 320,000 hours using
modern disks. Individually they are near 1.6 million.
This implementation is used in conjunction with a shared
Storage Area Network (SAN). Where each server comprises a host with access to
the entirety of the SAN.
Networking
Each server requires three ethernet ports. One for each
VLan. Through these the VM’s will be only able to reach their respective users
through the router, while the VM’s themselves will not have routing to other
VLans.
Reliability
Reliability is maintained by the duplication of hardware. In
the event that a physical server becomes inoperable, due to firmware/software
upgrades, or damage. The VM’s can be manually temporarily migrated to the
other, while normal operations are being restored.
Load Balancing
The load balancer VM is responsible for balancing the load
of incoming https connections to the running apache web VM’s. A utility such as
HAProxy running in the VM, allows this. Running the load balancer in a VM
ensures uptime, as another instance can be configured quickly.
Load balancing in this way ensures that capacity can scale
linearly. While this approach will incur a slight latency increase, this should
be made up for in the increased throughput multiple server instances provide.
Virtualising the load balancing, and web servers in this way
imparts important benefits. Outer-network communication is conserved for the
serving of client data, and intra-network communication is received by the VM’s
quickly. Not needing to go through a physical network switch, just to come back
into the LAN, it is handled inside the hypervisor on a virtual switch. This
allows the load balancer to communicate directly with each server to gather
load data, and make informed balancing decisions.
The usage of ESXi however, means that further provisioning
of extra resources to load balance, requires manual intervention. Unlike other
cloud platforms which offer this as an automated service.
Software
Virtualisation has been chosen for this design, as to
minimise the redundancy of hardware that comes with physically expanding a
datacentre. Dedicated tasks running each on a physical host, does not utilise
the full power of the hardware available. Virtualisation ensures the hardware
runs at an efficient capacity, in terms of hardware, space, and power.
The management of these devices is achieved through the ESXi,
bare-metal hypervisor. Rather than host based. Bare metal ensures the least
amount of non-virtualisation overhead. Through the web client, ESXi command
line, or various vSphere programs, the hypervisor can be configured to run VM’s
as needed.
ESXi is an example of paravirtualization. This has been
chosen when compared to other virtualisations techniques due to several
factors. Paravirtualization enhances the normal virtualisation process by enabling
guest hosts to communicate with the hypervisor directly for instructions that
are more efficient to be run by the hypervisor. However, operating systems are
required to be compiled with paravirtualization in order to support being
virtualised in this way.
Esxi also provides full virtualisation, which does not
require a specifically compiled operating system. Operating systems ran this
way are unaware that they are virtualised. ESXi fully virtualises the
environment in which the VM OS runs. All commands from the VM OS are run to
simulated components and hardware, through to the hypervisor. This requires the
hypervisor to manage any and all privileged commands from the VM OS. This comes
with some overhead to process and catch these commands.
While paravirtualization is preferred, it is understood that
some VM’s will eb run on these systems with the overhead of full virtualisation
as required.
SI staff will be able to access the file server through
FTPS, which will be forwarded through the router.
VMWare High Availability will provide the servers with the
failover capability required. It ensures that when a server fails, each
isolated VM is brought back online by booting them on the other server.
SAN (Storage Attached Network)
Incorporating the RAID array is the SAN. This SAN will be
attached to both GI and SI servers, allowing one to assume all stored VM’s as a
failover. This will be attached by Fibre Channel over Ethernet (FCoE), as the
throughput is expected to be nearing but below gigabit speeds. This makes FCoE
suitable for the purpose. Both hosts will use SCSI over FCoE to access the SAN
storage area. One storage area identified by a Logical Unit Number (LUN), will
be used and shared.
Direct Attached Storage(DAS) will not be used, other than to
boot the servers, to enable proper failover of VM’s. In the event of a hardware
failure, either physical server will need access to all information. Making a
SAN rather than a DAS solution, more applicable.
Backup
As the datacentre is only for the department, the VM’s can
be called to shutdown after hours, and their VM files can be backed up
automatically by the hypervisor, to an offsite backup solution. Security is
still maintained for this as the secure VM’s, including storage, can be wholly
encrypted.
This backup regimen also means that in the event of a
failover, the last disk backup can be downloaded and used in place of a
current/corrupt one. Continuing operations.
Solution
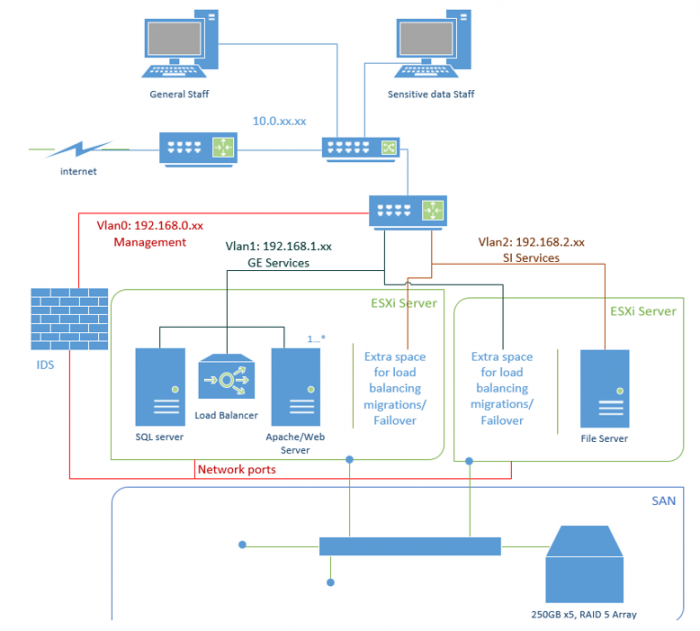
Figure 1 Proposed Topology of Datacentre
Network Topology
Topographically, the datacentre exists attached to the
central network of the administration with a router. This location allows the
datacentre to communicate with it’s users with the lowest latency possible.
Access to patch the servers directly is provided by the
management VLan.
Rack Cabinet
The standard width telephony cabinet would need to be a
minimum of fourteen standard units in height to hold the equipment specified.
The rack uses a top-of-rack routing design for network
connection, as it is assumed that the facilities for underfloor routing and
further aggregation do not exist.
In this scenario, the facilities for end-of-row routing are
also unneeded. Mainly due to the small size of the datacentre required, and the
redundancy of an additional rack for routing.
In future, when expanding, end-of-row routing would be the
preferred option.
Electrically the rack will require dedicated lines to ensure
that adequate amperage can be supplied. An uninterrupted power supply will be
used as an intermediary to power the rack. This will allow the servers, and
other potentially sensitive operations to shutdown gracefully upon power loss.
These servers are assumed to not require power during power cuts, as the employees
will not be able to work during these times.
Tier
This datacentre is a type two. It implements redundant
hardware to improve availability and ensure uptime. But does not provide the
multiple cooling, power paths necessary for Tier three. This design does
however implement redundant components, a server is able to fail and
functionality migrated to restore service. Which puts this design on track for
tier three, with future expansion and improvement.
References
Paris, j.-F. & Long, D. D., 2006. Using
Device Diversity to Protect Data against Batch-Correlated Disk Failures. [Online]
Available at: ftp://ftp.soe.ucsc.edu/pub/darrell/StorageSS-Paris-submitted-06.pdf
The Office for
Disability Issues, n.d. Disability prevalence estimates 2011/12. [Online]
Available at: https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/321594/disability-prevalence.pdf
…is a concept whereby an operating system is executed from a simulated environment rather than directly on any physical hardware. These virtualised instances are kept in containers such as files, which contain all the needed configuration and disk information needed to be instantiated.
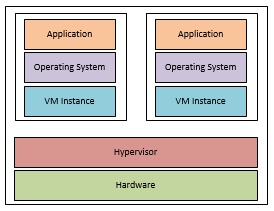
A normal PC exists in several layers as shown below. To virtualise it the hardware layer through to the application layer are containerised. With the hardware layer being replaced with configuration data, and the data of the system(OS and Applications) existing as a virtual disk(s) within this container.
These virtual machine(VM) instances are managed from a hypervisor. This is implemented in two main types:
Type 1 – Bare Metal Hypervisor
Examples include: ESXi, Xen, Hyper-v and KVM
The hypervisor runs on directly on the host’s hardware
acting as a “thin” operating system for the host machine. Guest OS’s run on the
hypervisor through virtual machine instances.
This approach is often preferred, as running directly on hardware allows for higher virtualisation efficiency.
Type 2 – Host Based Hypervisor
Examples include: VMware workstation and VirtualBox.
The hypervisor runs through the host operating system. The
hypervisor manages resources through the host operating system rather than
being able to directly manage these resources.
This type of virtualisation is very useful for temporary instances of machines, which would otherwise need to be placed on another physical machine. This approach in particular can be used to do live forensics on a revert-able disk image.
This approach is less efficient than type-1, and relies upon the interoperability that the host OS provides. For example a host OS, in some circumstances, may not passthrough the CPU’s virtualisation suites. Causing the hypervisor to rely on software emulation.
Virtualisation Implementation
So if a VM is supposed to work as if it were it’s own dedicated machine, how does the host hypervisor support this?
Virtual Cores
Each VM is assigned virtual cores (vCPU) upon creation. Each
of these is (usually) a virtualised thread of host CPU execution managed by the
hypervisor. In a hypervisor such as ESXi, the inbuilt resource scheduler
spreads workload over the physical CPU by taking into account vCPU workload,
and allocating physical CPU time to these vCPU’s as needed.
As such an underutilised internal http website VM would be given less physical CPU time, than an intensive video encoding VM running on the same host. These VM’s should still be given the physical CPU time needed to complete their executions, but would be able to share the resources of a capable host system.
Types of Virtualisation
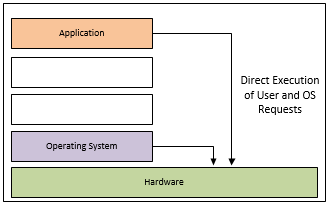
No Virtualisation
An example diagram of requests to the hardware in the normal
scenario without virtualisation.
Full Virtualisation
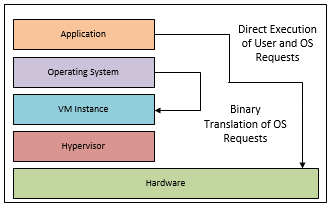
Full virtualisation emulates all instructions sent to the physical CPU by the VM. This is very performance intensive as binary translation is needed for VM OS requests.
Full virtualisation is mainly used in host based virtualisation.
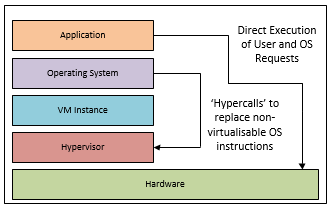
Paravirtualisation
Paravirtualisation lets most instructions run directly on the hardware of the host machine without emulation. The only instructions that are changed are non-virtualisable instructions, these are replaced with hypercalls that communicate directly with the hypervisor. The hypervisor will also provide other hypercall interfaces to the VM such as memory management, interrupt handling and timekeeping.
This involves the modification of the VM OS to handle all, non-privileged but still sensitive instructions. As the OS needs to be modified, any OS’s which are unmodifiable are not compatible with Paravirtualisation.
Hardware Assisted Virtualisation
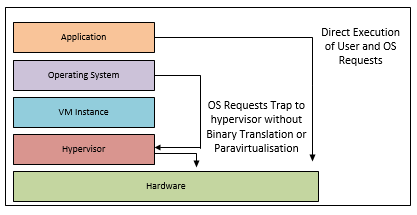
Hardware enhancements from AMD and Intel assist in the virtualisation process. Technologies such as VT-x (Intel) and AMD-v (AMD), allow the hypervisor to run in a root mode. Privileged and sensitive calls are automatically trapped by these technologies, removing the necessity of either binary translation or Paravirtualisation.
In 2008 under some workloads, hardware assisted
virtualisation performed worse than binary translation. As of writing, intel
boasts that the VT-x technology is as fast as native CPU utilisation.
Available since 2006, hardware assisted virtualisation
enhancements are used by VMware, Microsoft, Parallels and Xen, to name a few.